研究開発部のサウラブです。
本稿ではユーザがレシピの作成にかける労力を減らすために取り入れた、機械学習を利用した機能の一つについて 解説します。この機能を利用すると、ユーザがレシピのタイトルを入力することで、利用されるであろう材料が予測できます。
要約
- レシピのタイトルから材料を予測できるモデルを作りました。
- 投稿開発部と協力してレシピエディタに材料提案機能を追加しました。
App Storeで入手可能な最新のCookpadアプリ(v19.6.0.0)でこの機能を使用できます。
| 前 | 今 |
|---|---|
| Image may be NSFW. Clik here to view. 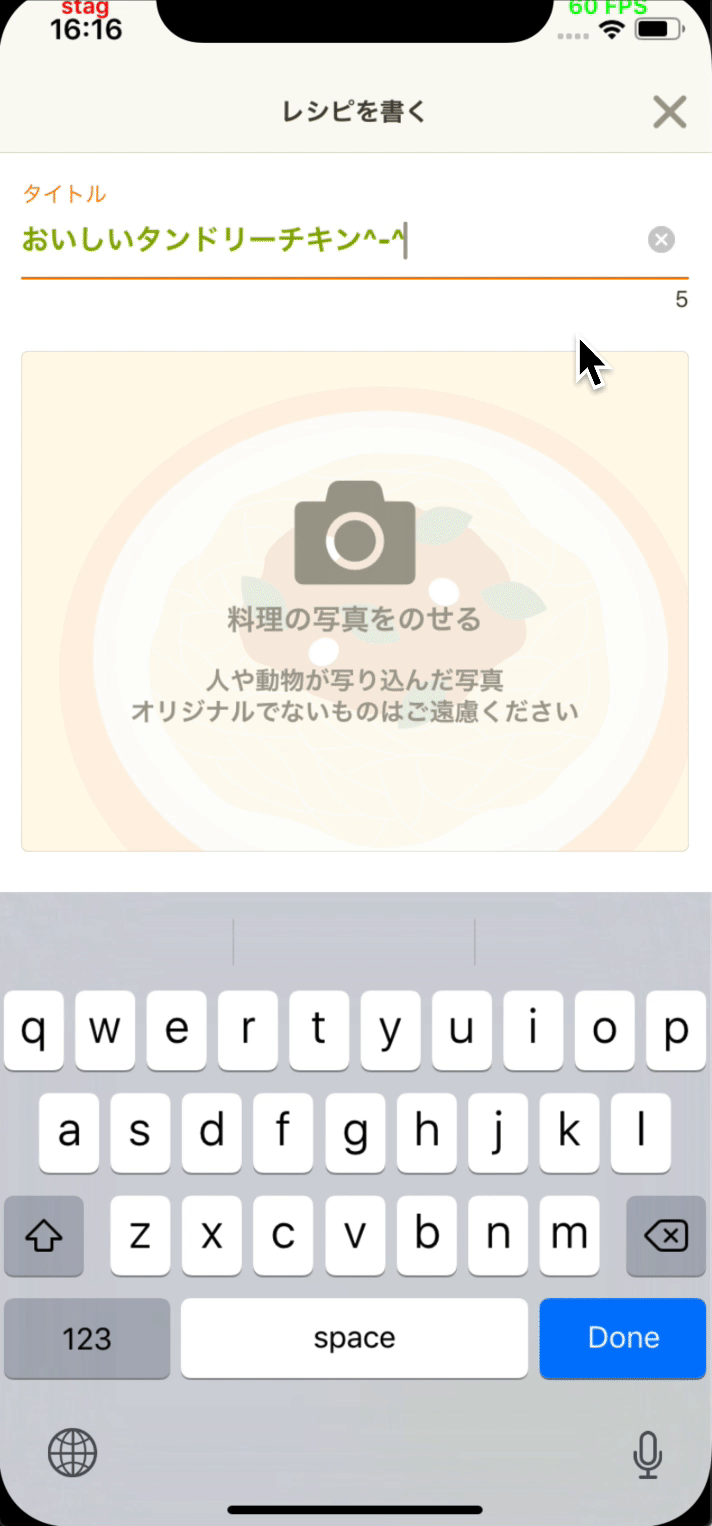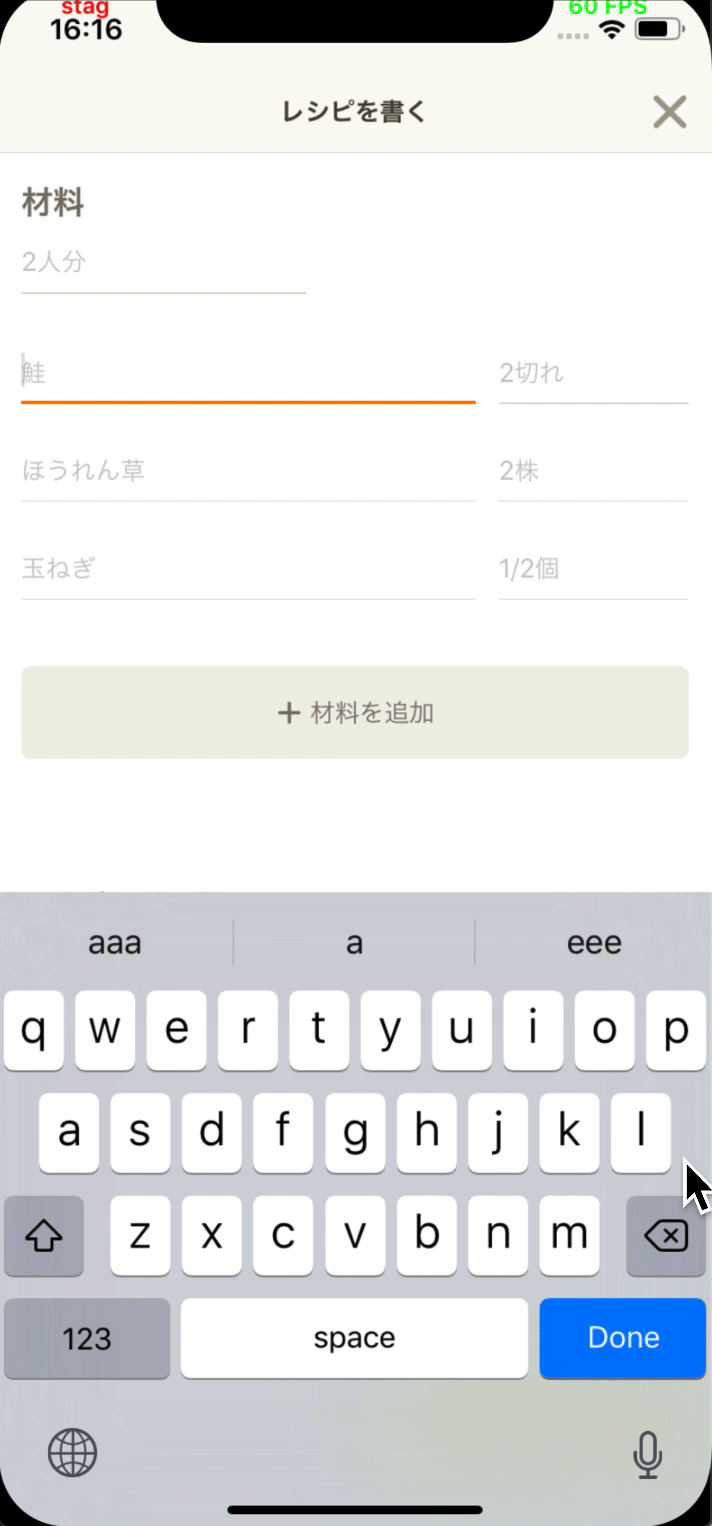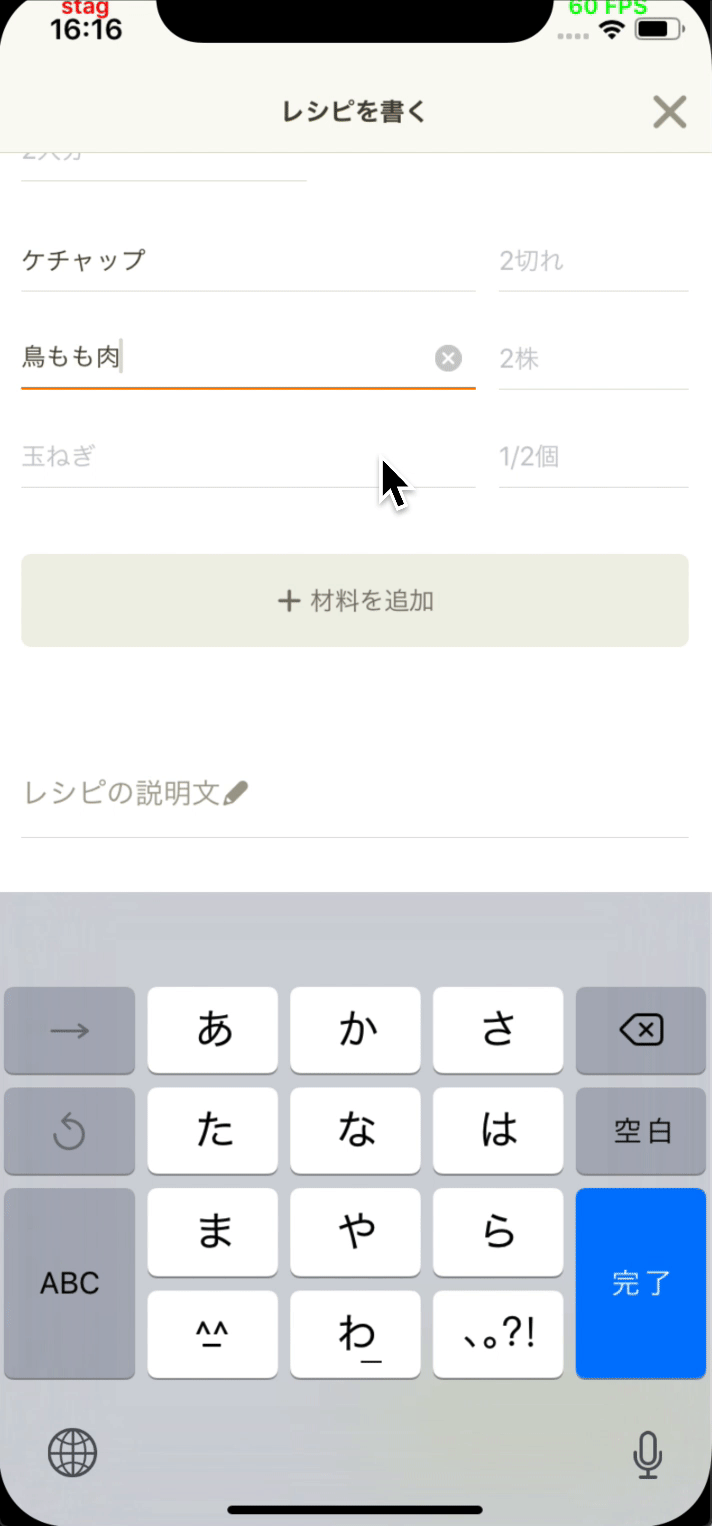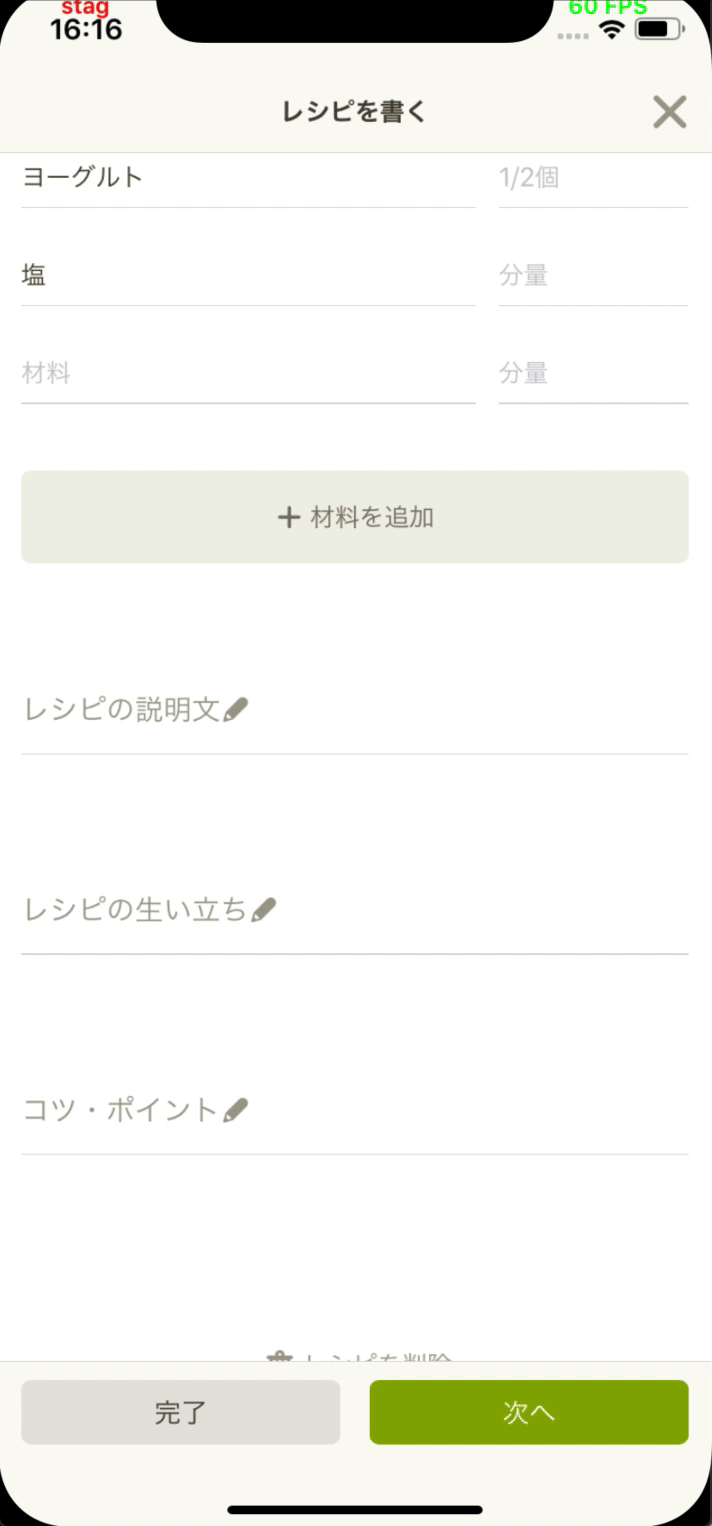 | Image may be NSFW. Clik here to view. 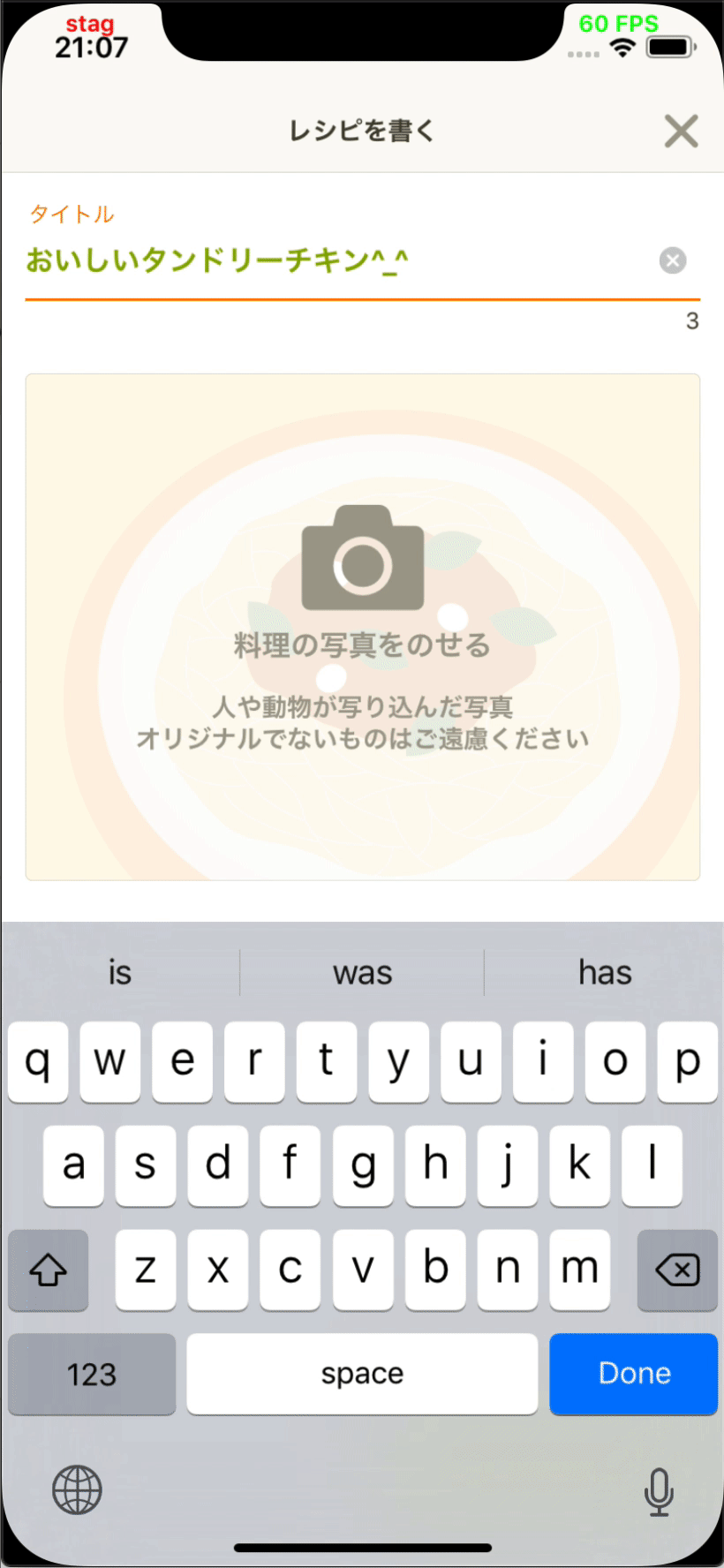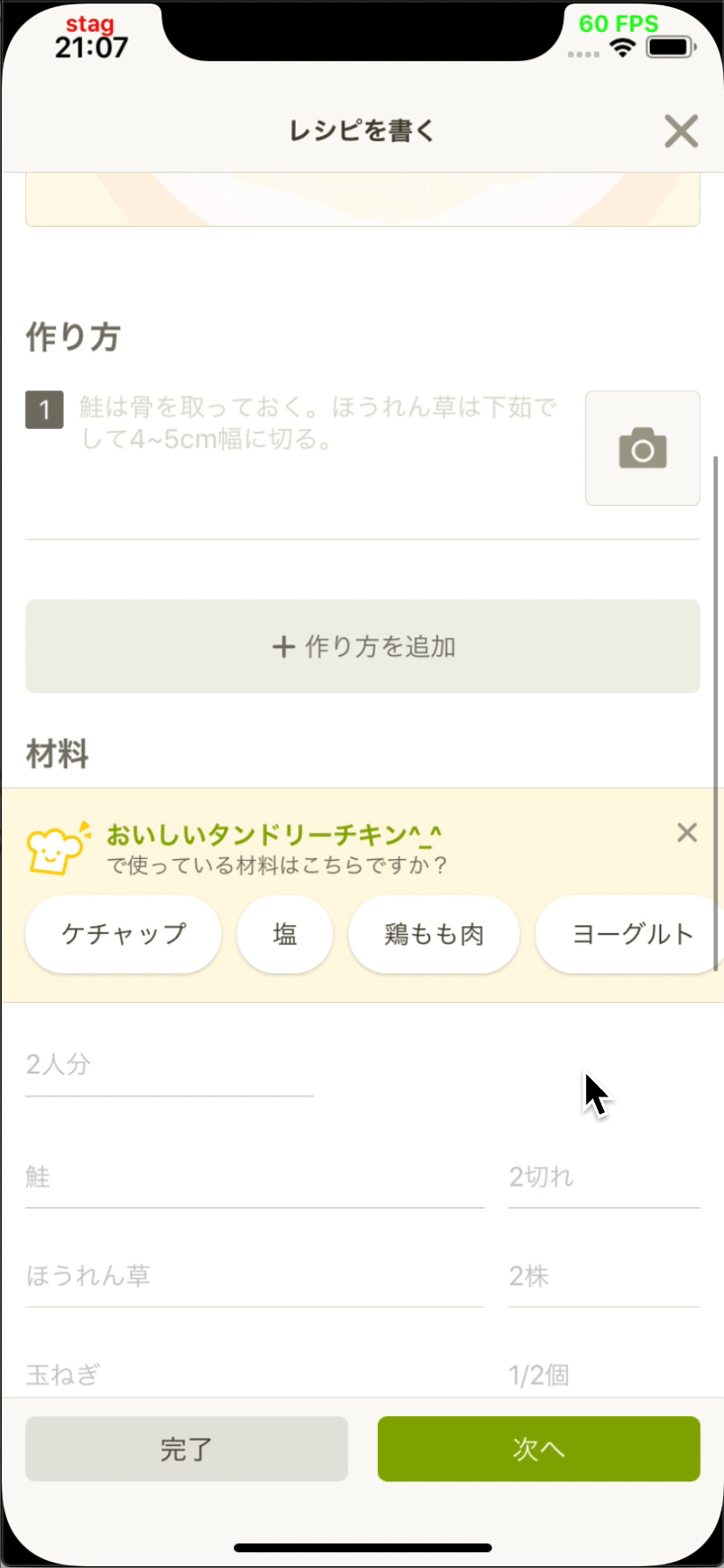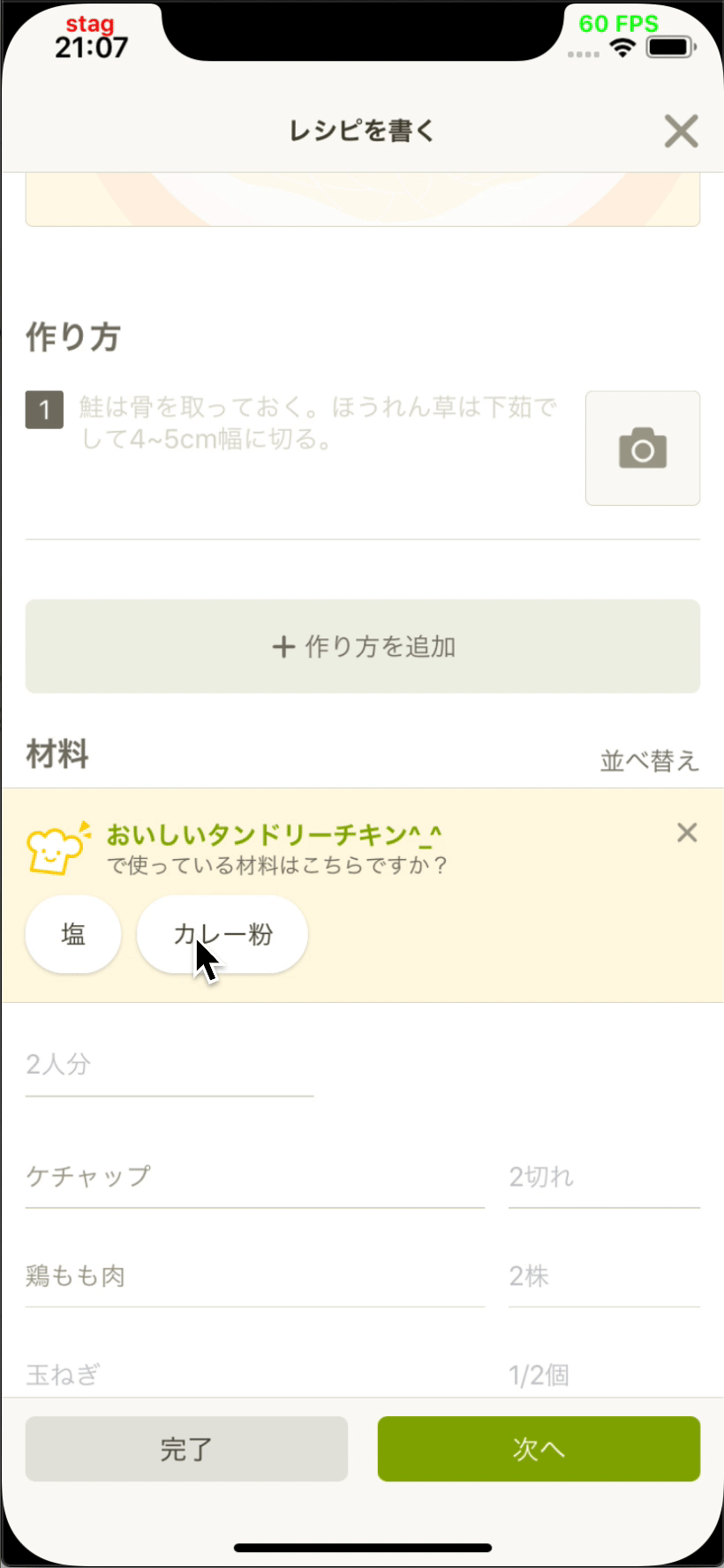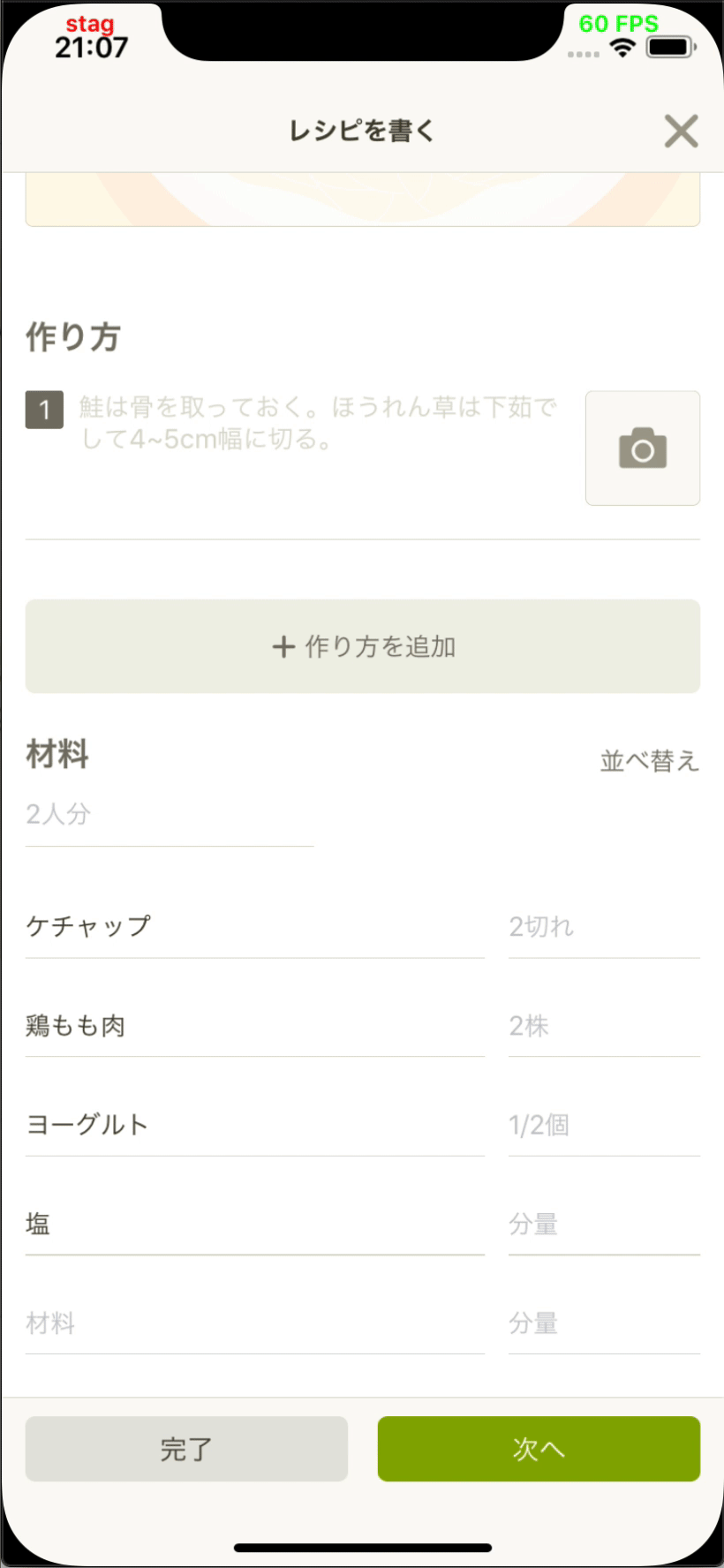 |
モデルはどうなっているか
1. Embed
Image may be NSFW.
Clik here to view.
- 学習(Training): Word EmbeddingとSentence Embeddingを学習してS3にアップロードします。(次のセクションで説明)
- 前処理(Preprocessing): 特殊文字を削除します。
多くのCookpadユーザーはテキストに特殊文字を使用しています。 例:"✧おいしい♡タンドリーチキン♡^-^✧"に特殊文字が含まれています:
♡,✧,^-^。特殊文字には材料に関する情報が含まれていないので、それらを削除します。特殊文字を削除するには、次のpython Functionを作成しました:
コードを表示する
import re defremove_special_characters(text): non_CJK_patterns = re.compile("[^"u"\U00003040-\U0000309F"# Hiraganau"\U000030A0-\U000030FF"# Katakanau"\U0000FF65-\U0000FF9F"# Half width Katakanau"\U0000FF10-\U0000FF19"# Full width digitsu"\U0000FF21-\U0000FF3A"# Full width Upper case English Alphabetsu"\U0000FF41-\U0000FF5A"# Full width Lower case English Alphabetsu"\U00000030-\U00000039"# Half width digitsu"\U00000041-\U0000005A"# Half width Upper case English Alphabetsu"\U00000061-\U0000007A"# Half width Lower case English Alphabetsu"\U00003190-\U0000319F"# Kanbunu"\U00004E00-\U00009FFF"# CJK unified ideographs. kanjis"]+", flags=re.UNICODE) return non_CJK_patterns.sub(r"", text)
- トークン化する(Tokenize): MeCabを使ってテキストをトークン化します。
- Embedding: Word EmbeddingとSentence Embedding モデルを使用して、Cookpadデータベース内の各レシピのタイトルをベクトルに変換します。
- 索引付け(Indexing): Faissを使用してベクトルにインデックスを付け(method = IndexFlatIP=Exact Search for Inner Product)、インデックスをS3にアップロードします。Faiss(Facebook AI Similarity Search)は、ベクトルの効率的な類似検索のためにFacebook AIによって開発されたライブラリです。 Faissは10億スケールのベクトルセットで最近傍検索をサポートします。
2. Search&Suggest (API Server)
Image may be NSFW.
Clik here to view.
- S3からWord EmbeddingモデルとSentence EmbeddingモデルとFaiss Indexをダウンロードします。
- Word EmbeddingモデルとSentence EmbeddingモデルとFaiss Indexをメモリにロードします。
- Embeddingモデルを使用して、入力されたタイトルをベクトルに変換します。
- Faissを使用してk個の類似するレシピを検索します。
- 類似するレシピの中で最も一般的な材料を提案します。

Embeddingsを学習する:
レシピのタイトルデータでWord Embeddingモデル(Fasttext)を学習します。
gensimでFasttextを使っていました。gensimはとても使いやすいです。
コードを表示する
from gensim.models import FastText # recipe_titles : [.....,牛乳で簡単!本格まろやか坦々麺,...]# tokenize recipe titles using MeCab and then train fasttext model# recipe_title_list(tokenized) : [...,['牛乳','で','簡単','!','','本格','まろやか','坦々','麺'],....] ft_model = FastText(size=100,min_count=5,window=5,iter=100, sg=1) ft_model.build_vocab(recipe_title_list) ft_model.train(recipe_title_list, total_examples=ft_model.corpus_count, epochs=ft_model.iter)
なぜFasttextを選んだのですか?
Fasttext(これは本質的にword2vecモデルの拡張です)は、各単語を文字n-gramで構成されているものとして考えます。 そのため、単語ベクトルは、これらの文字数n-gramの合計で構成されます。例:”中華丼”の単語ベクトルはn-gram”<中”、”中”、”<中華”、”華”、”中華”、”中華丼>”、”華丼>”のベクトルの合計です。Fasttextはサブワード情報で単語ベクトルを充実させます。それゆえ: - 稀な単語に対してもより良いWord Embeddingsを生成します。たとえ言葉が稀であっても、それらの文字n-gramはまだ他の単語中に出現しています。そのため、その Embedding は使用可能です。例:”中華風”は”中華丼”や”中華サラダ”のような一般的な単語と文字n-gramを共有することは稀であるため、Fasttextを使用して適切な単語のEmbeddingを学習できます。 - 語彙外の単語 - 学習用コーパスに単語が出現していなくても、文字のn-gram数から単語ベクトルを作成できます。
Sentence Embeddingモデルを学習します。
二つの Sentence Embedding モデルを試してみました:
Average of Word Embeddings:文は本質的に単語で構成されているので、単に単語ベクトルの合計または平均を取れば文のベクトルになると言えるかもしれません。 このアプローチは、Bag-of-words表現に似ています。これは単語の順序と文の意味を完全に無視します(この問題で順序は重要でしょうか?🤔)。
コードを表示する
import MeCab VECTOR_DIMENSION=200 mecab_tokenizer_pos = MeCab.Tagger("-Ochasen") defsentence_embedding_avg(title, model=ft_model): relavant_words = [ws.split('\t') for ws in mecab_tokenizer_pos.parse(title).split('\n')[:-2]] relavant_words = [w[0] for w in relavant_words if w[3].split('-')[0] in ['名詞', '動詞', '形容詞']] sentence_embedding = np.zeros(VECTOR_DIMENSION) cnt = 0for word in relavant_words: if word in model.wv word_embedding = model.wv[word] sentence_embedding += word_embedding cnt += 1if cnt > 0: sentence_embedding /= cnt return sentence_embedding
- トークン化する(Tokenize): MeCabを使用して文を形態素解析します。
- フィルタ(filter) :名詞、形容詞、動詞だけを残して、他の単語を除外します。
平均(Average): フィルタ処理した単語のWord Embeddingを取得し、それらを平均してタイトルベクトルを取得します。
Bi-LSTM Sentence Embeddings: Cookpadのレシピデータを使って教師あり学習によってSentence Embeddingを学習します。ラベルは2つのレシピ間のJaccard Similarityから導き出します。レシピを材料のセットと見なすと、2つのレシピ間のJaccard Similarityは次のように計算されます。 Image may be NSFW.
Clik here to view.
アイデアは、それらの間の高いJaccard Similarityを持つレシピのレシピタイトルベクトルをSentence Embeddingスペース内で互いに近くに配置することです。
- データセットを作成します: 2つのレシピのタイトルと、これら2つのレシピの類似度を表すJaccardインデックスを含む各サンプル行を持つデータセットを作成します。{title_1, title_2, Jaccard_index}
- 下のネットワークを学習します:
Image may be NSFW.
Clik here to view. 上記のネットワークは2つの設定で学習することができます:
上記のネットワークは2つの設定で学習することができます:
- Regression: g(-) : sigmoid と y = Jaccard Index
- Classification: g(-): dense+dense(softmax) と y = Jaccardインデックスから派生したクラスラベル 5クラスの分類設定で上記のネットワークを学習することによって学習されたF( - )は、最もよく機能するようです。ネットワークにとって、回帰問題よりも分類問題の方が解きやすい場合があります。
Kerasでネットワークを実装する:


コードを表示する
from keras import backend as K from keras import optimizers from keras.models import Model from keras.layers import Embedding, LSTM, Input, Reshape, Lambda, Dense from keras.layers import Bidirectional import numpy as np defcosine_distance(vects): x, y = vects x = K.l2_normalize(x, axis=-1) y = K.l2_normalize(y, axis=-1) return K.sum(x * y, axis=-1, keepdims=True) title_1 = Input(shape=(MAX_SEQUENCE_LENGTH,)) title_2 = Input(shape=(MAX_SEQUENCE_LENGTH,)) word_vec_sequence_1 = embedding_layer(title_1) # Word embedding layer(fasttext) word_vec_sequence_2 = embedding_layer(title_2) # Word embedding layer(fasttext) F = Bidirectional(LSTM(100)) sentence_embedding_1 = F(word_vec_sequence_1) sentence_embedding_2 = F(word_vec_sequence_2) similarity = Lambda(cosine_distance)([sentence_embedding_1, sentence_embedding_2]) similarity = Dense(5)(similarity) y_dash = Dense(5, activation='softmax')(similarity) model = Model(inputs=[title_1, title_2], output=y_dash) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit([train_title_1, train_title_2], y) # [train_title_1, train_title_2], y are respectively input titles and class label np.save('bilstm_weights.npy', F.get_weights())
- 前のステップで学習したF(-)を文のEmbeddingとして使用します:
コードを表示する
from keras.models import Model from keras.layers import Embedding, LSTM, Input, Reshape, Lambda, Dense from keras.layers import Bidirectional import numpy as np title = Input(shape=(MAX_SEQUENCE_LENGTH,)) word_embedding = embedding_layer(title) F = Bidirectional(LSTM(100)) sentence_embeddding = F(word_embedding) sentence_embedding_model = Model(input=title, output=sentence_embedding) sentence_embedding_model.layers[2].trainable = False sentence_embedding_model.layers[2].set_weights(np.load('bilstm_weights.npy')) defsentence_embedding_bilstm_5c(text): txt_to_seq = keras_tokenizer.texts_to_sequences([mecab_tokenizer.parse(text)]) padded_sequence = sequence.pad_sequences(txt_to_seq,maxlen=MAX_SEQUENCE_LENGTH) return K.get_value(sentence_embedding_model(K.cast(padded_sequence,float32)))[0]
結果
以下はサービスにおける利用率です。例えば、3 out of 5 suggested ingredients matches actual は 5 個 suggest したうち 3 個が利用された割合です。
| 3 out of 5 suggested ingredients matches actual(%) | 2 out of 5 suggested ingredients matches actual(%) | |
|---|---|---|
| Average of word embeddings | 53% | 80% |
| Bi-LSTM Sentence Embeddings | 50% | 76% |
Average of word embeddings(これはBag-of-Wordsに似ています)はBi-LSTM Sentence Embeddingよりもこの問題に適しています。これは、レシピのタイトルは短いテキストであるために、単語順序の情報は材料を予測するのにはあまり役に立たないからだと思われます。
まとめ
- レシピのタイトルから材料を予測できるモデルを作りました。
- 投稿開発部と協力してレシピエディタに材料提案機能を追加しました。
いかがでしたでしょうか。 Cookpadでは、機械学習を用いて新たなサービスを創り出していける方を募集しています。 興味のある方はぜひ話を聞きに遊びに来て下さい。