技術部 SRE グループの鈴木 (id:eagletmt) です。
クックパッドでは Amazon ECS をオーケストレータとして Docker を利用しています。Docker 自体は2014年末から本番環境にも導入を始めていましたが当時はまだ ECS が GA になっておらず、別のしくみを作って運用していました。2015年4月に GA となった ECS の検討と準備を始め、2016年より本格導入へと至りました。クックパッドでは当初から Hakoというツールを用いて ECS を利用しており、Hako の最初のコミットは2015年9月でした。
https://github.com/eagletmt/hako/commit/7f95497505ef78491f3f68e9d648204c7c9bb5e2
当時は ECS に機能が足りずに自前で工夫していた部分も多かったのですが、ECS やその周辺サービスのアップデートにより不要になったものもいくつかあります。今回はその中からいくつか紹介しようと思います。
クレデンシャルを環境変数に設定する
データベースに接続するときのパスワードのように、アプリケーションコードにハードコードすべきではなく、安全に保存しなければならないクレデンシャルが存在します。そういった値を扱うために、クックパッドではクレデンシャルを Vaultに保存し、Hako の定義ファイル上で Vault に保存された値を参照する記法を導入し、デプロイ時には Hako が Vault から値を取得して ECS のタスク定義に注入するようにしました。
 このようにすることでクレデンシャルが Git リポジトリ内に入ることを防ぎ、また ECS のタスク定義を閲覧する権限を絞ることでクレデンシャルに対する権限管理を行うようにしました。
このようにすることでクレデンシャルが Git リポジトリ内に入ることを防ぎ、また ECS のタスク定義を閲覧する権限を絞ることでクレデンシャルに対する権限管理を行うようにしました。
このしくみは長いこと運用されてきており今もまだ残っていますが、現在では ECS のアップデートによりクレデンシャルを与えるための機能が追加されたので、それを利用するようになっています。
https://docs.aws.amazon.com/AmazonECS/latest/userguide/specifying-sensitive-data.html
これにより Parameter Store や Secrets Manager、KMS によってクレデンシャルの安全な保存と権限管理を達成でき、タスク定義の閲覧を制限する必要がなくなったり、Vault を自前で運用したり Hako のようなツールで工夫する必要もなくなりました。
1つのロードバランサーを複数のアプリで共有する
ECS には ELB と連携する機能が当初からありましたが、1つの ECS サービスに対して1つのロードバランサーしか関連付けることができませんでした。つまり1つのアプリに対して1つのロードバランサーが必要でした。これは機能的には問題無いのですが、ELB のロードバランサーには数に比例した料金が設定されており、どんなに利用が少なくても一定の料金がかかります。公開されている Web アプリの場合は24時間アクセスがきますが、社員が時々使うだけのようなスタッフ向けアプリの場合はロードバランサーの分の料金の割合が高くなります。そのため、できるだけロードバランサーを共有して料金を抑えたいという事情がありました。一方でロードバランサーを共有するとロードバランサー毎のログやメトリクスが複数のアプリで混ざったものになってしまう問題があるため、これを許容できるようなワークロードに限ってロードバランサーを共有することにしました。
そこでロードバランサーを共有するケースでは ECS と ELB の連携機能を使わず、独自にサービスディスカバリを実装し1つのロードバランサーから複数のスタッフ向けアプリにプロキシするようなしくみを作りました。1つのロードバランサーから EC2 上に起動した nginx にプロキシし、その nginx の設定は consul-template から生成されるようにしてホスト名に応じて各アプリにプロキシされるようにしています。
 このしくみのもう少し詳しい説明は https://speakerdeck.com/eagletmt/ecs-woli-yong-sitadepuroihuan-jing?slide=28にあります。
このしくみのもう少し詳しい説明は https://speakerdeck.com/eagletmt/ecs-woli-yong-sitadepuroihuan-jing?slide=28にあります。
以前はこのような工夫でロードバランサーの料金を抑えていたのですが、2016年に ALB が登場し、2019年に ALB が Host ヘッダによってルーティングを変更できるようになったことで状況が変わりました。これにより ECS サービスに対応するターゲットグループを1つのロードバランサーに複数関連付け、Host ヘッダの値でルールを作成することで、ロードバランサーを複数アプリで共有することができます。
 このようなしくみにすることですべて AWS の機能で済ませることができるようになり、Consul を運用したり各アプリにプロキシする nginx を運用したりする必要がなくなりました。
このようなしくみにすることですべて AWS の機能で済ませることができるようになり、Consul を運用したり各アプリにプロキシする nginx を運用したりする必要がなくなりました。
gRPC サーバを ECS で動かす
クックパッドではマイクロサービス化の過程で gRPC を導入し、Ruby や Go 等で実装された gRPC サーバが動いています。gRPC サーバを動かし始めた当時は ALB がサポートしていなかったため、gRPC サーバと通信するためのしくみを自前で作る必要がありました。ここで必要なものは gRPC サーバのサービスディスカバリとプロキシで、前述のロードバランサーを共有したい状況と似ています。しかしこの時点で社内にサービスメッシュが整備されていたため、gRPC のプロキシには Envoy を利用できそうでした。gRPC サーバ向けに Envoy の SDS API *1を実装すればサービスディスカバリについても実現できそうだったので、そのようなしくみを作って gRPC サーバを ECS で動かすようにしました。また、非 gRPC のサーバではエラーレートやレイテンシといった基本的なメトリクスが ALB に依存していたので、gRPC サーバの手前にも Envoy を置くことで Prometheus にメトリクスを入れることにしました。
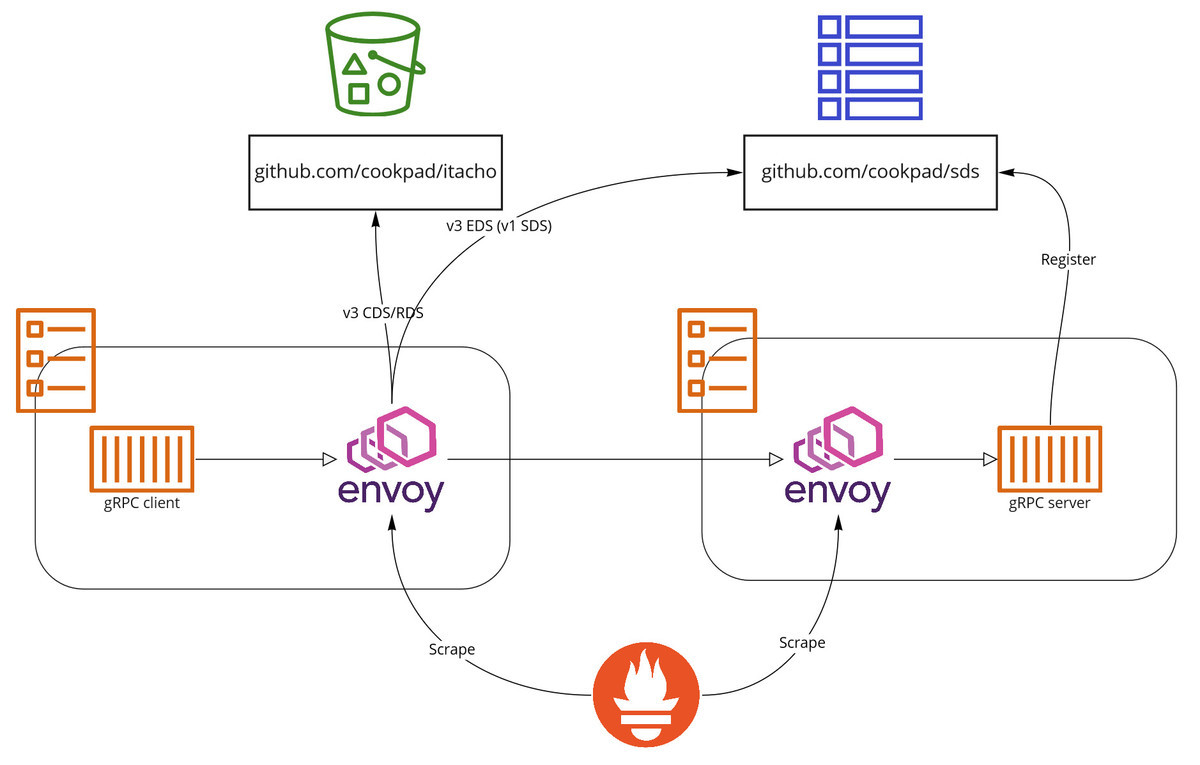 このしくみの詳細は https://techlife.cookpad.com/entry/2018/05/08/080000や https://logmi.jp/tech/articles/320715を参照してください。
このしくみの詳細は https://techlife.cookpad.com/entry/2018/05/08/080000や https://logmi.jp/tech/articles/320715を参照してください。
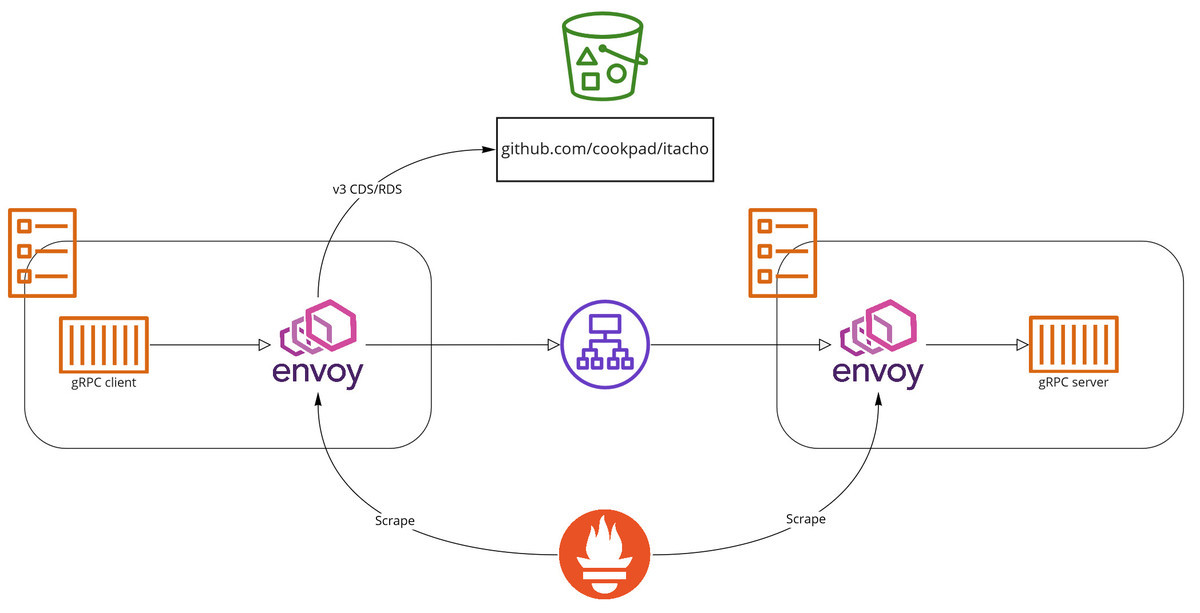
このように gRPC サーバを ECS で動かすには工夫が必要だったのですが、2020年に ALB が gRPC をサポートしたことにより独自のしくみ無しで gRPC サーバを動かせるようになりました。現時点で ALB では gRPC レベルのステータスコードをメトリクスからもログからも確認することができないため、間に Envoy を置いてメトリクスやログをとっている点は変わってませんが、https://github.com/cookpad/sdsやそれに登録するためのしくみを運用することなく gRPC サーバを ECS で動かせるようになっています。
まとめ
ここまでで紹介したもの以外にも、コンテナインスタンスの drain がサポートされたことにより ECS クラスタのスケールインが容易になったり、タスク内のコンテナ間に依存関係を定義できるようになったことでサイドカーコンテナのヘルスチェックが通るまでメインのコンテナの起動を遅らせることができるようになったり、daemon scheduling strategy でデプロイしたタスクが drain 対象になったときに最後に停止されるようになったことでたとえば daemon scheduling strategy でデプロイしている cAdvisor で最後までメトリクスをとれるようになったりと、ECS が GA になった当時と比べるととても使いやすくなっています。
このようにクックパッドでは AWS を活用しつつも自分たちのニーズに合わせてしくみを自作し、社内の基盤を構築してきました。そして AWS のアップデートにより自作のしくみが不要になったときは積極的に自作を廃止し、できるだけ AWS の機能だけで済むようにしてきました。自分たちの目的のために必要であれば自作できることも大切ですが、メンテナンスや運用の手間をできるだけ減らすために、目的を達成できる範囲内でできるだけ自作を減らすことも大切だと考えています。我々 SRE グループはそのようなバランス感覚を持ちながら必要なものを開発していける仲間を募集しています。
https://cookpad.jobs
*1:v1 当時の名前。現在では v3 EDS API になっている