こんにちは。SRE の小川 (@coord_e) です。先日の投稿にあった通り、クックパッドはレシピサービスをグローバル版に統合しました。サービスの統合に伴って、開発や運用のインフラもグローバルチームで利用されているものを使うことになりました。
運用インフラの中でも特に大きな違いとして、日本とグローバル版ではコンテナオーケストレーションの仕組みが異なっています。日本では Amazon Elastic Container Service (ECS) を使ってコンテナを実行していますが、グローバル版では Amazon Elastic Kubernetes Service (EKS) の上でコンテナを実行しています。
また開発面ではデプロイフローに大きな違いがあります。日本では、アプリケーションの新しいリビジョンのデプロイは ChatOps によって行なっていました。main ブランチに PR がマージされ、CI パイプラインが新しいリビジョンのコンテナイメージをビルドした後、開発者が Slack チャンネルでコマンドを実行(発言)することで、そのリビジョンのデプロイを行います。日本版での開発フローは下の記事に詳しく記載されています。
一方、グローバル版では、アプリケーションリポジトリでの PR マージ後に自動でデプロイまでが行われます。後に詳しく説明しますが、これは Fluxという OSS を活用して実現されています。全体的に GitOps の流れに乗っており、アプリケーションの Git リポジトリへの push を起点としてのちのデプロイの全ての行程が自動で進行するようになっています。 fluxcd.io

なお、コンテナオーケストレーションやデプロイの方法含め、One Experience 後にグローバルと日本の間でインフラをどうしていくかは議論の最中です。本稿で紹介する手法は、基本的に短期的に運用上の問題点を解決するためにフォーカスした選択をしています。
リバートによるロールバックとその課題
さて、新しいリビジョンをデプロイした後に、それが原因となった問題が発覚した場合、その変更を速やかに取り消す必要があります(ロールバック)。これまで、グローバル版ではロールバックはコミットのリバートによって行われていました。変更を取り消すコミットを新たに積み、それをデプロイするという流れです。これは GitOps の流れから逸れることなく、通常のデプロイワークフローに乗ってオペレーションができるという点で優れています。しかし、グローバル版での開発を進めるにつれて、リバートによるロールバックの課題がいくつかわかってきました。
- 通常のデプロイフローに乗っているため、変更が巻き戻るまで時間がかかります。特に CI 上でのテスト実行のオーバーヘッドが無視できません。
- 一部 Flaky なテストも存在しており、それをリトライしているとテストが全て通るまで長い時間がかかってしまう場合があります。
- さらにデプロイは直列に行われ、直前に他のデプロイが起きているとそのデプロイが終わるまで待つ必要があります。
- 通常のデプロイフローに乗っているため、変更に承認が必要です。私たちは GitHub 上で main ブランチへのマージに一名以上の Approve を必須としていますが、障害対応においてはこのオーバーヘッドもあります。
- もちろん障害発生時にはこれをバイパスしてマージできるように特権を用意しておく方法もあり得ますが、障害発生時にのみ特権を使うという判断や制御は難しくなることが予想されます。
基本的に、障害発生時には、ユーザーへの影響を最小限にとどめるために即座にロールバックを完了したいです。しかし、リバートによってロールバックを行うとどうしても時間がかかりすぎてしまいます。もちろんデプロイフローを高速化するのは有効ですが、テストの実行やイメージのビルドは避けられないため、例えば原因の特定から1分以内にロールバックを開始するといったことは難しいでしょう。
これまでの日本版の開発では問題発生時に1分もかからずロールバックを開始できていました。今回 One Experience で日本チームがグローバル版の開発に合流しましたが、ロールバック手順が整備されておらず、障害が発生した際にすぐに回復できずに 40 分ほどサービスをダウンさせてしまう出来事がありました。これをきっかけに、日本版での開発と同様にグローバル版にも即時にロールバックを実行できる仕組みを整備することにしました。
私たちが利用している Flux では、マニフェストを同期しているリポジトリでのリバートによってロールバックを実現するのが筋のようです1。しかし、後述するように私たちはマニフェストリポジトリの自動更新を行っているためそれを止める必要があったり、また Helm Controller のデプロイ待ちの問題があったりと、単なるマニフェストリポジトリのリバートでは即時ロールバックの要件を満たすことができませんでした。そこで、私たちは通常のデプロイフローからは外れた、即時ロールバックのための独自のオペレーションを構築することにしました。
GitOps から外れる: どこで流れを止めるか
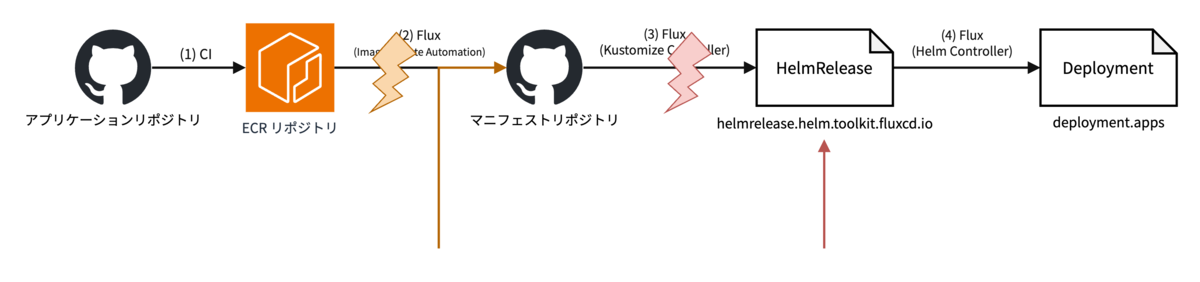
通常のデプロイフローから外れるということは、自動デプロイの流れをある点で停止することを意味します。まず、現在のグローバル版のデプロイの詳しい流れを下の図に示します。なお、グローバル版では Deployment を含むアプリケーションのリソースは Helmチャートとしてパッケージ化されており、Helm リリースの Values からデプロイするイメージのタグを注入しています。

- アプリケーションのリポジトリで新しいコミットが push されると、CI がコンテナイメージをビルドし ECR リポジトリにイメージを push します。
- これを Flux の Image Update Automation 機能が自動的に検知し、アプリケーションに対応する HelmReleaseの
.spec.valuesに記述されたイメージのタグを更新するコミットを作成してマニフェストリポジトリへ push します。HelmRelease というのは Flux が Helm のリリースを管理するために用いるカスタムリソースで、.spec.valuesに Helm リリースの Values を記述しておくと Helm Controllerが自動でhelm installやhelm upgradeを実行します。 - マニフェストリポジトリの内容は Kustomizeで構成されており、Flux の Kustomize Controllerがマニフェストリポジトリの内容を自動的にクラスタへ反映するように設定されています。これにより先ほど push された
.spec.valuesの変更がクラスタ内の HelmRelease オブジェクトに反映されます。 - HelmRelease オブジェクトが変更されると、Flux の Helm Controller がそれを検知し、自動的に
helm upgradeを実行します。これによって最終的に新しいイメージのタグが Deployment の spec まで反映され、Deployment のロールアウトが起こります。
ロールバックにおいては、アプリケーションの Deployment の spec に記述されているイメージのタグを問題発生以前のものに書き換えることが目標となります。単に直接 Deployment を書き換えるのは、その後リポジトリに push があると Flux がそれを上書きしてしまうため適切ではありません。では、どのようにしてこれを達成すると良いでしょうか。
方法1. Helm より上流でイメージのタグを戻す
まず考えられるのが、HelmRelease までの部分でデプロイの流れをせき止め、ロールバック先のイメージのタグを強制的に使わせるという方法です。上の図でいうと、次のどちらかになるでしょう:
- イメージのタグを ImagePolicyで固定し、(2) を実質的に停止する
- (3) を停止し、HelmRelease の
.spec.valuesにあるイメージのタグを直接書き換える
どちらのやり方でも HelmRelease の .spec.valuesが戻り、それを検知した Flux の Helm Controller が helm upgradeを実行して正しく Deployment の spec にあるイメージのタグを変更し、ロールバックが実現できるでしょう。
しかし、この方法では長めの待ち時間が発生してしまう問題が考えられます。Helm Controller はデフォルトで helm upgrade実行後に各種リソースが ready になるまで待つようになっており、私たちもこの挙動を採用しています(helm upgrade --waitと同じ挙動)。
fluxcd.io
そして、Helm Controller はひとつの Helm リリースに対して helm upgradeを直列に行うため、ロールバックしようとした際に進行中のデプロイがあるとそれが終わるまで、すなわち Pod が全部入れ替わって ready になるまで待つことになってしまいます。現状、これには場合によって 5 分を超える時間が必要で、一刻も早くロールバックを行いたい状況においてこれを待つのは適切ではありません。そして、このデプロイ完了待ちを中断する方法は今の所ないようです。もちろん Helm Controller を再起動すれば止まりますが、ロールバック対象の Helm リリースとは関係のない Helm リリースの制御にも影響するため、筋の良いやり方とは言えません。
これらの理由から、ロールバックの適用で Helm Controller に頼らない方法を採用する判断をしました。
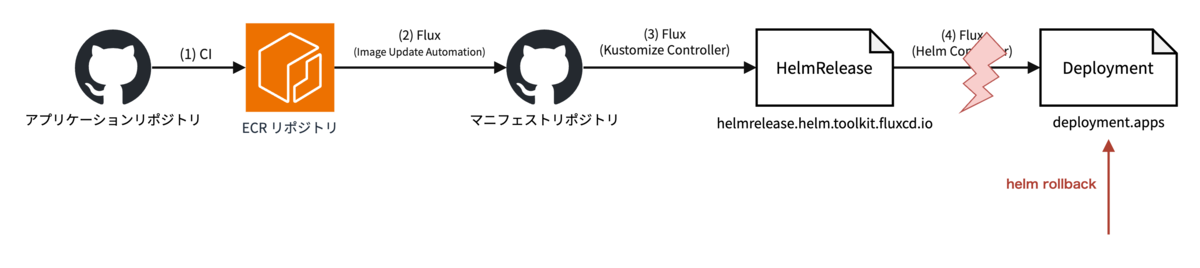
方法2. 直接 Helm リリースのリビジョンを戻す
Helm には Helm のリビジョン管理があります。helm upgradeのたびに Helm はクラスタ内に Helm リリースの完全なマニフェスト情報の履歴を保存しています。Helm では helm rollbackコマンドでその情報を使って以前のリリースの状態を復元することができます。
helm.sh
これを使う場合、上流から .spec.valuesが更新された時に Helm Controller がリリースの状態を上書きしてしまわないように HelmRelease の同期を停止する必要があります。上の図でいうと (4) を停止し、最後の Deployment を直接(Helm の実装を使って)書き換えるアプローチになります。この方法なら既に Helm Controller による helm upgradeが進行中でも即座にロールバックを開始できます2。Deployment はロールアウトの途中であっても変更があれば即座に新しいロールアウトを開始するため、helm rollbackで Deployment の spec が書き換わり次第すぐにイメージが戻り始めます。
kubernetes.io
この方法は直ちにロールバックが開始できるという点に加えて、イメージのタグ以外の要素のロールバックにも使えるという点で優れています。これまで説明していませんでしたが、私たちはアプリケーションイメージに加えてアプリケーションの Helm チャートそれ自体を変更することがあります。例えば、コンテナに割り当てるリソース量や渡す環境変数を変更する場合がこれにあたります。そのような変更を取り消したいような時にも、helm rollbackによって同じ手続きで対応できるわけです。
ChatOps コマンドとしての実装
つまり、Flux による HelmRelease の管理を停止し、helm rollbackを手元から実行すれば良いのでしょうか?しかし、ロールバックを実行するのは開発者であり、インフラの管理者ではありません。その点で、手元から実行するには次のような問題があります:
helm rollbackは、そのチャートに含まれるリソースをおおかた更新する操作であり、実行には相応の権限を必要とします。開発者にはそのような権限がありません(し、付与するのも適切ではありません)。helm rollbackがロールバック先として受け付けるのは Helm リリースのリビジョンであり、アプリケーションの Git リビジョン(コミットハッシュ)ではありません。そして、開発者はアプリケーションのコミットハッシュから Helm リリースのリビジョンを探す方法を知らないかもしれず、対応の遅れや不正確さに繋がります。- メンバーによって Kubernetes や現行のデプロイフローに対する習熟度はまちまちであり、こういった手動のオペレーションの正しい手順を見つけて実行するのには時間がかかってしまうかもしれません。
つまり、開発者の代わりに helm rollbackを実行する主体が必要になります。Web アプリケーションとして用意するなどいくつか方法は考えられますが、今回は Slack のチャットボットのコマンドを実装してそこから helm rollbackを実行することにしました (ChatOps)。ChatOps によるロールバックには次のような利点があります:
- ロールバックを行ったという事実が即座に共有され、コミュニケーションが容易になります。
- 記録がよく残り、パーマリンクとして用いることもできます。
- オペレーションの方法について、実際にそのオペレーションを実行していない人も知ることができ、今後のオペレーションに活かすことができます。
このような性質は、特にロールバックのような迅速な対応とコミュニケーションを両立しなければならない局面において非常に有効です。私たちは日本で長い間 ChatOps によるデプロイとロールバックを実践してきたこともあり、今回も開発者向けのインターフェイスとして ChatOps を採用することに決めました。幸い、私たちは ChatOps コマンドを容易に開発できる基盤を整備しており、今回もそれに乗ることで Slack とのインターフェースについて意識せずに ChatOps コマンドを開発することができました。
ロールバックのスラッシュコマンド
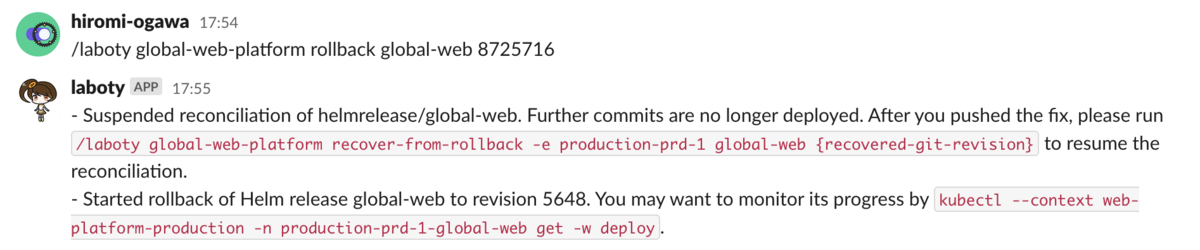
Slack 上で次のように発言することでロールバックを開始できるような実装を作成しました。なお laboty というのは、先ほど説明した内製 ChatOps 基盤の名前です。
/laboty global-web-platform rollback {アプリケーション名} {ロールバック先のコミットハッシュ} 日本の開発フローではデプロイが明示的な操作だったため、ロールバックでは一つ前のリビジョンに戻していました。一方グローバル版の自動デプロイの環境下では、ロールバック先となるリビジョンは明らかではなく、開発者が明示的に指定する必要があります。そこで helm rollbackのためにロールバック先の Helm リリースのリビジョンを知る必要がありますが、私たちの実装では開発者が指定したアプリケーションのコミットハッシュから対応する Helm リリースのリビジョンを自動的に決定するようになっています。
また、私たちは自動デプロイの結果を Slack チャンネルに通知しています。これには Flux の Alert 機能を使っているのですが、デプロイ進行中に helm rollbackで割り込んだ場合にロールバックの完了がデプロイ完了として通知されてしまうおそれがありました。そのため、helm rollbackの実行前にデプロイ通知のための Alert も停止しています。
まとめると、このスラッシュコマンドは下の操作を順番に行います。
flux suspend helmrelease {アプリケーション名}flux suspend alert {アプリケーション名}-deploy-notifierhelm rollback {アプリケーション名} {ロールバック対象のリビジョン}
実際にはそれぞれの操作は CLI の呼び出しではなく Go API を使った Kubernetes API の呼び出しとして実装されています。Flux の suspend 操作は対象オブジェクトの .spec.suspendフィールドを true にすることで実現でき、それを sigs.k8s.io/controller-runtime/pkg/clientパッケージを使ってオブジェクトのパッチ操作として実装しています。helm rollbackについては Helm が Go SDK を提供しており、それをそのまま利用しています。
helm.sh
復旧のスラッシュコマンド
上で説明した通り、今回実装したロールバック操作は、自動デプロイを停止します。これはロールバックを要するような緊急時には適切ですが、アプリケーションリポジトリ上で問題が解消されたらその状態でデプロイを行い、開発を再開するために自動デプロイを再開する必要があります。私たちは、このために次のようなスラッシュコマンドを実装しました。
/laboty global-web-platform recover-from-rollback {アプリケーション名} {回復したコミットハッシュ} このスラッシュコマンドは、自動デプロイを再開するためのものであるため、回復したコミットハッシュを渡す必要はないと思われるかもしれません。しかし、先に説明した私たちのデプロイフローでは、アプリケーションリポジトリの main ブランチに PR がマージされてから HelmRelease の .spec.valuesまでイメージのタグが伝搬するまである程度時間がかかります。そして開発者が recover-from-rollback を実行したタイミングでまだ回復したコミットが HelmRelease に反映されていないと、自動デプロイを再開した途端に古い(回復前の)イメージのデプロイが始まってしまいます。そのようなミスを防ぎ、意図したコミットのイメージからデプロイが再開することを確実にするため、回復したコミットハッシュを引数として受け取ってそれを確認するような実装にしています。具体的には、このスラッシュコマンドは下の操作を順番に行います。
- アプリケーションの HelmRelease の
.spec.valuesに回復したコミットハッシュのイメージタグが記述されていることを確認 flux resume alert {アプリケーション名}-deploy-notifierflux resume helmrelease {アプリケーション名}

まとめ
Flux と Helm を使って GitOps をしているグローバル版プラットフォームにおいて、開発者による即時ロールバックを実現した方法について紹介しました。冒頭で紹介したとおり、リバートによってロールバックをしていた時は障害発生から復旧まで40分ほどかかってしまうこともあったのですが、このしくみの導入によって問題の発覚後直ちにロールバックが開始できるようになりました。
もちろん障害時にサービスへの影響を最小限にとどめるという意味でもロールバックは大事なことですが、サービス開発の側面においても、いつでも直ちにロールバックできるという認知は速度を上げるために大事だと考えています。今回の即時ロールバックの導入は、そういった面でも意味のある取り組みになったのではないかと思います。
- https://github.com/fluxcd/flux2/discussions/2916↩
- helm rollback はリリースのステータスが pending-upgrade だったとしても無視します↩