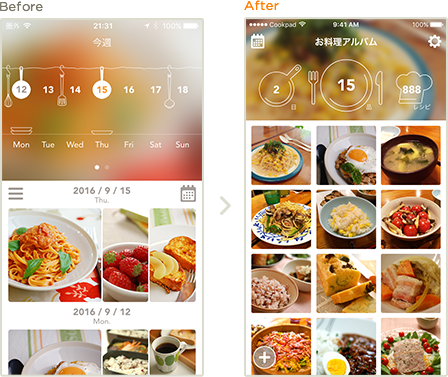
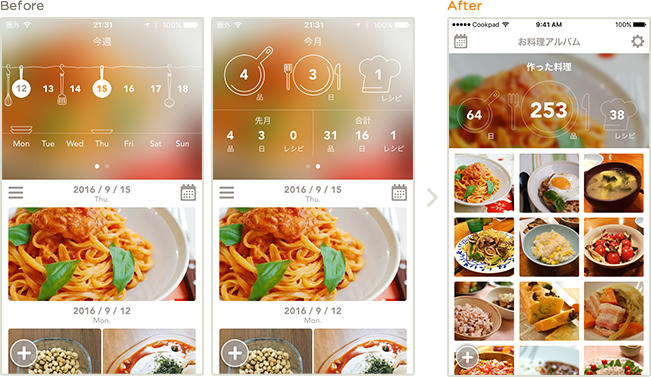
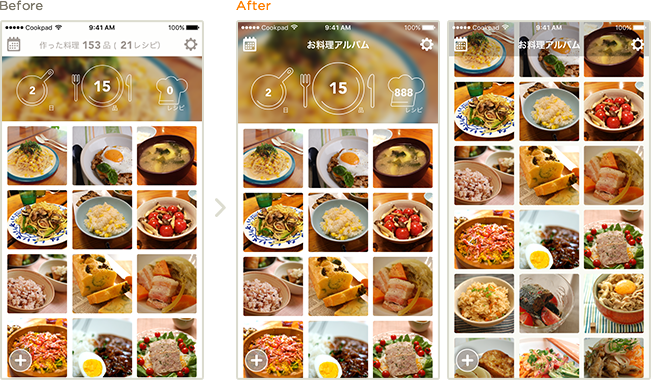
こんにちは。検索事業部 ディレクターの五味です。クックパッドにレシピを探しに来るユーザーの体験向上を使命に、レシピ検索に纏わる技術・UIの改善、プラットフォームをまたいだサービス全体の編成に関わる仕事をしています。
プロダクトのリリースや改善にあたり、ユーザーテストによる仮説検証は不可欠です。今回は、先日クックパッドAndroidアプリで初めて、Google Playのベータテスト機能を使ってユーザーテストを行った話をご紹介します。
ベータテストに踏み切った背景
クックパッドアプリでのユーザーテストはこれまでも実施してきましたが、すべて通常版アプリにテストを内包する手法をとってきました。
しかしあるプロジェクトで、これまでのユーザー導線を根底から変える規模の改変を含んだプロダクトのテストを行う必要が生じました。アプリ全体の体験から大きく異なるテストプロダクトを通常版アプリに統合することはコストが高すぎる上、メリットもありません。
そこで、テスト版アプリを通常版と別バイナリとして配信でき、またその対象者も既存のアプリユーザーから募ることのできる、Google Playのベータテスト機能を利用してみることにしました。
既存アプリで大胆な価値検証ができた
1つの仮説にとことん集中し、その仮説を満たす最低限の機能のみで構成されたプロダクトを実際のユーザーに配信して反応を測る。今回ベータテストを実施してもっとも良かった点は、そのような大胆な価値検証を、クックパッドという既存アプリで遂行できたことです。
今回のテストは、従来であれば、新規の別アプリを作って検証する等の手段を取らざるを得ない内容でした。しかしその手法では、将来的に既存アプリをテストプロダクトでリプレイスする可能性がある場合、その際に生じるネガティブな反応の大きさを計り知ることができません。
この検証は、ユーザーが普段使っているアプリがテスト版に置き換わるというGoogle Playベータテストの仕様によって可能になったものでした。

ベータテストの実施で考慮すべき点
ここからはベータテストに興味をお持ちの方向けに、テスト実施の際に一考いただきたいポイントをご紹介します。この3項目は今回我々が苦慮した点でもあります。
1. オープン?クローズド?
ベータテストにはGoogle Appsアカウントでテスターを管理できるクローズドベータと、テスター数の上限だけを設定するオープンベータの2種があります。テストの目的や要件をよく考慮し、状況に合った方式を選ぶことが大切です。
今回のケースでは数千単位のテスターを必要としており、アカウント管理のコストを考慮すると、本来はオープンベータを採択するべき案件でした。しかし以下の理由から、敢えてクローズドベータを選択しました。
- 仮説がきちんとターゲットに響くか確かめるため、テスト参加者を既存アプリの利用パターンから選出した方に限定したい
- テストプロダクトがMVP検証のため既存機能を大幅に削ってあるため、注意事項をご理解いただいた上で参加いただきたい
結果、テスト参加者は想定より大幅に少なくしか集客できませんでしたが、この施策段階では条件に合うユーザーにテストアプリを使っていただくことが、数を揃えるより優先度が高かったと考えています。
2. ベータテスト参加のユーザー体験
サービスによって差異はあるとは思いますが、ユーザーはこのようなテストアプリを利用することに熟達していないという点を忘れてはいけないと思います。
試しにアプリのベータテストに参加してみると、テスター募集からテスト参加、テスト版アプリのインストールまで、画面遷移は多く、導線も複雑です。Google Play Developer Consoleでの作業の簡単さと引き換えに、Google Play側の各画面は編集できる領域が少なく、使われる用語もユーザーにとってわかりやすくはないように思えます。

テスト参加の敷居を下げ、多くのユーザーにテスターとなってもらうため、以下のような準備をしました。
・テスト参加ご案内ページ
テストにスカウトしたユーザーに概要を知っていただくためのページです。参加規約や、テストアプリを入手するまでのフロー解説、お問い合わせ導線をまとめています。

・テスター専用FAQ
事前にFAQを作成。テストアプリ内のわかりやすい場所に導線を設けました。テストを途中離脱したい場合の解説等も併記しています。

・ユーザーサポートチームの協力
サポートチームに担当をつけてもらい、事前にテストアプリの機能表や想定問答集を共有。専用チャットルームも準備して密にコミュニケーションを取れる体制を作りました。
3: テスターの募集方法
テストアプリの配信はGoogle Playに助けていただけますが、参加者確保はすべて自前で行う必要があります。今回はこの点になかなか苦戦しました。
リクルーティング導線として、今回はAndroidアプリのスタートスクリーンにテスター募集のバナーを表示しました。しかしこの導線のパフォーマンスが予想以上に厳しく、3000人にバナーを表示しても、100名程度しか反応が得られませんでした。てこ入れ策として対象ユーザーにメール配信も行いましたが、そちらも思うほど効果がなく、最終的にテストアプリをインストールしていただけたのは200名弱という結果になりました。

今後に向けて
今回のベータテストでの1番の収穫は、既存アプリで作り上げられている環境を制約とせず、新しい機能に集中した急進的なテストプロダクトを、実際に今のアプリを使っているユーザーに試用いただけたことです。
テストにご参加いただいたのに利用反応がなくなってしまった方に、プロジェクトメンバーが直接電話インタビューを行い、リアルなご意見をいただいて悄気てしまう日もありました。しかしそこからのプロダクト改善は目覚ましく、そのようなネガティブな反応をいただけたのも、既存のクックパッドアプリから更新する形でテストアプリをお使いいただくことができたおかげだと思います。
次はより多くのテスターに使っていただくなど、段階に合わせたテスト方法も検討していく必要があります。折しもGoogle社からオープンベータの機能増幅やテスター参加導線の強化がいくつか発表されていますので、それらもうまく取り入れ、より柔軟にテストを活用できるようにしていきたいと考えています。
なおクックパッドでは、このようなサービス改善に一緒に取り組み続けてくださる方を、職種問わず募集しています 。ご興味のある方はこちらからどうぞ。