クックパッドの海外向けのAndroidアプリを開発している @rejasupotaroです。海外チームでは英語圏だけでなく、スペイン語圏やアラビア語圏や、その他いろいろな地域・ユーザーの環境に合わせてサービスをローカライズしながら展開しています。

東南アジアや南米では日本に比べるとネットワークは不安定で遅く、現地に行って自分たちのサービスを使うと読み込みの遅さに愕然とすることがあります。レシピサービスにとって画像の読み込みの速度は重要なので、これまでもレイテンシ、フォーマット、圧縮率、キャッシュ、画像サイズ、リクエストの優先度、プリロードなどさまざまな最適化を試みてきました。今回はスレッドプールのサイズについて考察しました。
非同期処理とスレッドプール
Androidには、UIを操作することができる唯一のメインスレッドと、APIや画像のリクエスト、DBの読み書きなどの時間のかかる処理でメインスレッドをブロックしないためのワーカースレッド(ユーザーから見えない裏側で実行されることからバッググラウンドスレッドとも呼ばれる)の、2種類のスレッドがあります。
Androidではメインスレッドとワーカースレッドの処理のやり取りする方法はいろいろありますが、その一つにExecutorフレームワークがあります。Executorは内部にキューを持ち、Runnableを実装したタスクをexecuteメソッドで実行します。図にすると下のような感じです。
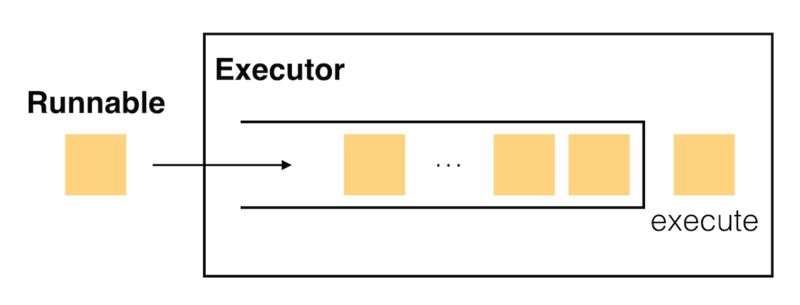
メインスレッドでリクエストを生成して、ワーカースレッドでタスクを処理するようなデザインパターンを、プロデューサー・コンシューマーパターンと呼びます。このコンシューマーすなわちワーカースレッドはタスクが要求されるたびに生成することもできますし、スレッドプールを使って再利用することもできます。待機させておくスレッド数や、最大のスレッド数などは実装に依存します。
Picassoのスレッドプール
私のプロジェクトでは画像の読み込みに Picassoを使っています。Picassoは内部にFixedThreadPoolを持っていますが、ネットワークの接続状況に応じて自動的にプールサイズを調整するようになっており、以下のように変動します。
| 通信規格 | スレッドプールサイズ |
|---|---|
| WiFi, WIMAX, Ethernet | 4 |
| LTE, HSPAP, EHRPD | 3 |
| UMTS, CDMA, EVDO | 2 |
| GPRS, EDGE | 1 |
| 該当なし | 3 |
しかし、いくつかの理由からこの値は最適でないのではないかと思っていました。
通信規格と速度は必ずしも一致しない

Facebook Launches 3 New Open-Source Tools For Android Developers | TechCrunch
通信規格というのは実際の通信速度を示すものではありません。日本ではLTEよりWiFiの方が速いですが、ブラジルでは逆にWiFiの方が遅かったりします。
I/Oの待ち時間が長いほどスレッド数を増やした方が効率が良さそう
"画像読み込み"という処理を分解すると、
- 画像のリクエストをタスクにしてキューに送る
- ワーカーがキューからタスクを取り出して画像のリクエストをサーバー送る
- ストリームをデコードしてBitmapに変換する
- メモリとファイルにキャッシュとして書き込む
- ワーカーからメインスレッドにBitmapを渡して描画する
このように多くの時間がI/O待ちで占められています。なので、ネットワークが遅いほどスレッドの数を増やした方が良さそうに思います。
検証環境
今回は東南アジアや南米を想定して下り500kbps前後の環境に最適化します。Wikipediaによると EDGEの最大スループットは473.6kbpsらしく、ちょうどユーザーの環境に近いのでエミュレーターのネットワークスピードとレイテンシをEDGEに設定して検証しています。
画像のフォーマットはWEBPで品質は70、実際の表示サイズをパラメーターに与えてリクエストしていて、大きくても100KB以下になっています。
ワーカースレッド数と待ち時間
画像のリクエストの到着がポアソン分布に従い、処理時間が指数分布に従い、ワーカースレッドがc個からなるM/M/cキューと見なした場合、待ち行列理論が適用できるので、平均到着率・平均サービス率を調べることでワーカーの利用率、システムの内のタスクの数、システムの平均待ち時間を算出することができます。
平均到着率はアプリの使い方によって変わるので正確に求めることは難しいのですが、ワーカースレッド数を1に固定した状態で、何も考えずに適当に検索したりしながら測定したら、以下のようになりました。
- 平均到着時間: 0.24 sec =>到着率: 4.166
- 平均サービス時間: 0.75 sec =>サービス率: 1.333
0.24秒ごとにリクエストが来ていたので、逆数をとると1秒間に4.16回のリクエストが来ていることになります。タスクの処理時間は0.75秒だったので、1秒間に1.3個のタスクをさばくことができることが分かります。到着率とサービス率から、ワーカーの利用率は以下の式で求めることができます。
ρ (利用率) = λ (到着率) / cμ (ワーカー数 * サービス率)
利用率は3.125になり、1を超えているということはリクエストを消化できずに、キューにタスクがどんどんたまり続けている = ユーザーが画像の表示を待つために操作が中断される状態になるということが分かりました。ワーカー数を増やした場合に、ワーカーの利用率やキューの長さやキューの滞在時間がどうなるかを表にしました。
| c (Number of workers) | ρ (Worker utilization) | L (Average tasks in system) | W (Average time spent in system) |
|---|---|---|---|
| 4 | 0.7814 | 5.1401 | 1.2336 |
| 5 | 0.6251 | 3.5734 | 0.8576 |
| 6 | 0.521 | 3.2521 | 0.7805 |
| 7 | 0.4465 | 3.1625 | 0.759 |
| 8 | 0.3907 | 3.1362 | 0.7527 |
| 9 | 0.3473 | 3.1285 | 0.7509 |
| 10 | 0.3126 | 3.1264 | 0.7504 |
M/M/cキューの計算式はちょっとゴツいので Queueing theory models calculatorで計算しました。
ワーカー数が3以下だと利用率が1を超えてしまうためキューの長さや待ち時間を計算することができません。またこの表からスレッド数を7より増やしてもほとんど効果がないと言うことが分かります。 待ち行列理論は、コンピューターに限らず一般的な事象に対しての式なので、今回のケースでそのまま適用可能かというのを少し考えみましょう。
待ち行列とスレッドプール
ワーカーの利用率ρを計算しましたが、これはあくまでもワーカーがタスクを持っているというだけで、CPUの利用率とはまた別になります。コンピューターはI/Oなどでコンテキストスイッチが発生するため、ワーカーがタスクを持っていてもCPUを使っているとは限りません。
待ち行列理論はよくレジとレジに並ぶ客に例えられますが、今回のケースではレストランのウェイターと客の関係に近く、注文を取ったあとウェイターは料理が出てくるまでの間に厨房の前でぼーっとしているのではなく他の客の注文が取れそう、ということです。
調べてみたところ、スレッドプールサイズの最適化にはいくつかの式が提案されていることが分かりました。 たとえば Calculate the Optimum Number of Threadsよると、I/Oバウンドな処理は以下の式に当てはめます。
threads = number of cores * (1 + wait time / service time)
この式の wait time / service timeは、タスクに対するCPUが遊んでいる時間と計算している時間の比率になります。ExecutorとDownloaderにフックして測定したところ、平均待ち時間は756msで平均応答時間は1082msなりました。
threads = number of cores * (1 + wait time / service time)
= number of cores * (1 + 756 / (1082 - 756))
= number of cores * 3.32上記の式から係数は3.32となり、CPUコア数にI/O待ちが長くなるほど大きくなる係数がかかっているので感覚的には良さそうに見えます。私たちのサービスのユーザーに多い2コアの端末では6.64スレッド、4コアの端末では13.28スレッドという値になりました。待ち行列理論の式と照らし合わせてみても係数3は妥当な値に見えます。
13スレッド…多すぎない?
画像読み込みではPicassoの他には Glideというライブラリがあり、人気を二分していますが、GlideのスレッドプールサイズはCPUのコア数に等しくなるように設定されています。 ということでPicassoもGlideもだいたい2〜4スレッドになっていることが大半ということで、上記の計算結果の13スレッドはもしかしたら多いのかもしれません。
スレッドプールサイズが大きすぎる場合、同期のためのロックでのリソース消費であったり、スレッドはいるだけで数K〜Mのメモリを消費してしまうので、あまり大きな値を設定するのは避けたいです。
また、アプリでのスレッドプールサイズの最適化はリソースを使い切ることが目的ではなく、ユーザーが快適にアプリを使えるようにするのが目的なので、リソースをかつかつに使ってしまうとその他の動作に影響を及ぼす可能性があります。そのため、もう少し詳しくこの問題を見ることにしました。
ユースケースを考えてみる
話は変わりますが、出張の際には現地のユーザーさんに声を掛けてユーザーテストをさせてもらうことがあります。ユーザーテストは「今日のメニューを決めてください」のようなシナリオをやってもらいますが、ユーザーは画像の読み込みを待ってから次のページを見る、というような使い方をしていたことを思い出して、実際自分もそうだなと思いました。
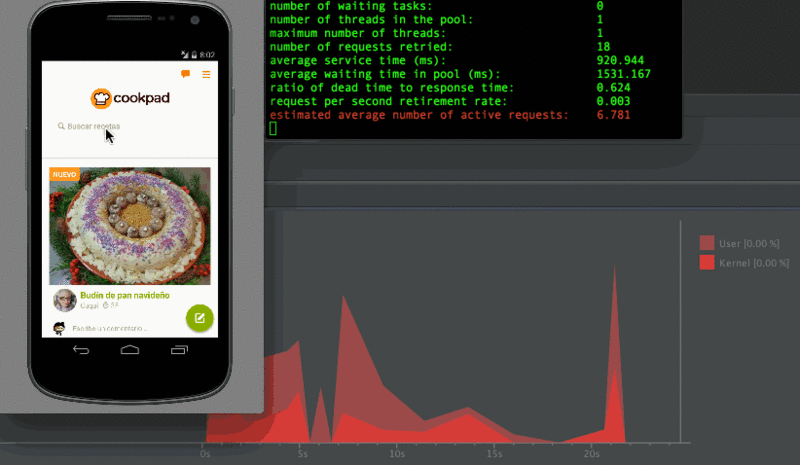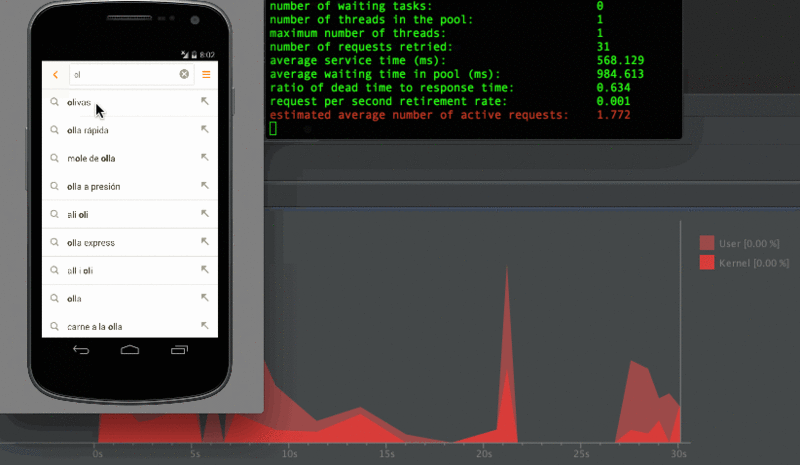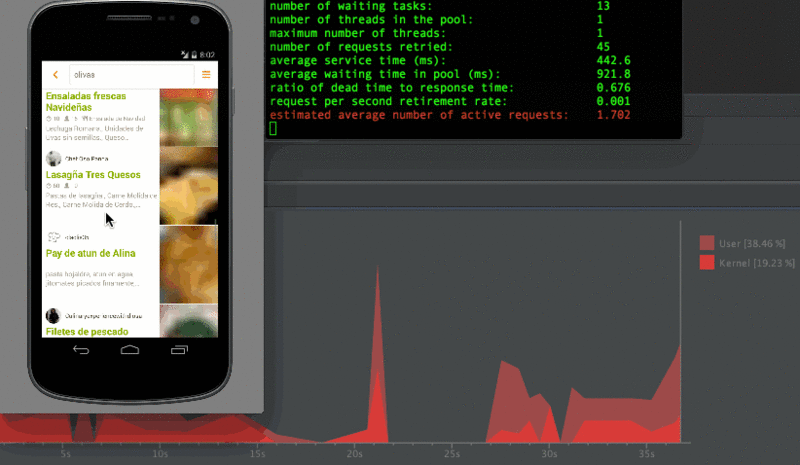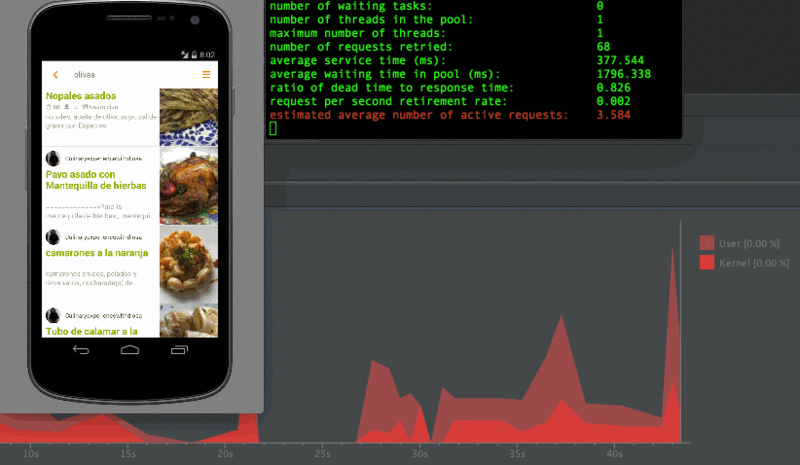
こんな感じに計測してたけど実際のユーザーは検索していきなり全力で下までスクロールしたりしない!
つまり、画面内に表示される画像の数よりワーカースレッド数を多くしても無駄になってしまう可能性が高いのではないかと思いました。私たちのアプリだと一画面に表示される画像の数は6〜8個(解像度に依存)くらいなので、ワーカー数の最大値は8が適当でしょう。
まとめ
以上のことから私たちのアプリでは CPUコア数 * 3と 8の小さい方を取ると最適になりそうという結果になりました。
Math.min(Runtime.getRuntime().availableProcessors() * 3, MAX_NUMBER_OF_IMAGES_IN_SCREEN)
たとえば、2コアの端末で3G回線のユーザーのデフォルトのワーカースレッド数は3だったのが、この式では6スレッドになるので、厳密にどれくらい改善するかは数字にしづらい(スレッド数によってユーザーの行動が変わり、到着率が変わり、計算結果が変わる)のですが、もしキッチリ画像の表示を待った場合に比べると、画像の待ち時間が半分になり、レシピが2倍早く決まる!(可能性がある)ということになります。
今回の検証ではこのような結果になりましたが、どういうサービスでどこに最適化するかによって結果は変わってくると思います。
たとえば、つぶやきサービスで「ラーメンの様子です」というつぶやきと共に貼られたラーメンの画像は重要度はそこまで高くないので、貴重なリソースは画像読み込みのワーカースレッドより他に回した方がいいと思いますし、レストラン検索サービスでリソースをケチって1スレッドにすると、デートの店選びに使いたいのに、忘年会の幹事で早く店を決めないといけないのに画像の表示が遅くてイライラするなど、そういうこともありそうですね。
